Extracting Data and Structure from Charts and Graphs for Analysis, Reuse and Indexing
Abstract
Charts and graphs are ubiquitous forms of data representations, appearing in scientific papers, textbooks, reports, news articles and webpages. These visualizations leverage human visual processing to efficiently convey large amounts of quantitative information, and to illustrate trends and differences in the data. But, while people can easily interpret data from charts and graphs, machines cannot directly access this data. Today, a vast trove of information is locked inside data visualizations. In this project, we develop tools that allow machines to extract, data and structure from such visualizations and thereby enable data analysis, reuse and new forms of indexing across the collection of existing charts and graphs. All together the tools will provide a novel computational infrastructure for knowledge integration and sharing and impact a broad range of users including scientists, journalists, economists, social scientists, and educators.
Specifically, the project addresses three main goals. First, it develops computational models for interpreting visualizations to extract the underlying data, graphical marks, and mappings that relate the data to mark attributes. The approach is informed by recent work on human perception and cognition of visualizations. The aim is to build generalized computational models that can accurately extract data from visualizations and also mimic the way people decode information from visualizations. Second, it supports development of a suite of applications that enable analysis and repurposing of visualizations and data. Third, it applies automated visualization interpretation techniques at Internet scale and develops a search engine that indexes visualizations based on their underlying data and graphical structure. The search engine will accelerate data-driven analysis and discovery by facilitating browsing and retrieval of data that is currently locked in computationally inaccessible visualizations.
Current People
Maneesh Agrawala: Professor at Stanford University (PI)
Enamul Hoque: Assistant Professor at York University
Dae Hyun Kim: PhD student at Stanford University
Publications
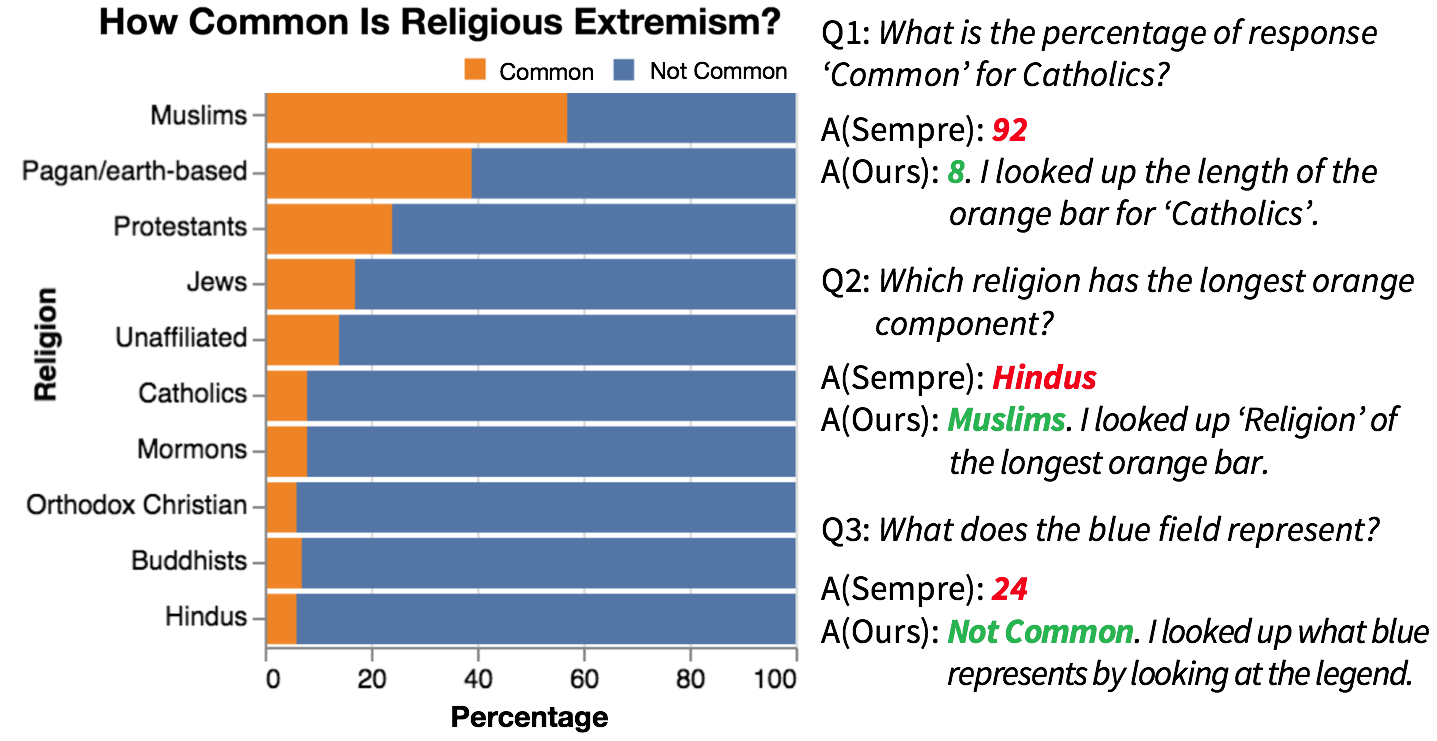
Dae Hyun Kim, Enamul Hoque and Maneesh Agrawala
ACM Human Factors in Computing Systems (CHI), Apr 2020. To Appear.
PDF | Supplemental PDF | Code & Data

Enamul Hoque and Maneesh Agrawala
IEEE Trans. on Visualization and Computer Graphics (INFOVIS), 26(1), Jan 2020. pp. 1236-1245.
PDF | MP4 | Demo

Dae Hyun Kim, Enamul Hoque, Juho Kim and Maneesh Agrawala
User Interface Software and Technology (UIST), Oct 2018, pp. 423-434.
PDF | MP4 | Data
Jonathan Harper and Maneesh Agrawala
IEEE Trans. on Visualization and Computer Graphics, 24(3), March 2018, pp. 1274-1286.

Jonathan Harper and Maneesh Agrawala
User Interface Software and Technology (UIST), Oct 2014, pp. 253-262.
PDF | MP4 | Chrome Extension | Code

Nicholas Kong, Marti A. Hearst and Maneesh Agrawala
ACM Human Factors in Computing Systems (CHI), Apr 2014. pp. 31-40.
PDF | MP4 | Interactive Document Viewer

Nicholas Kong and Maneesh Agrawala
IEEE Trans. on Visualization and Computer Graphics (INFOVIS), 18(12), Dec 2012. pp. 2631-2638.
PDF | Interactive Gallery
Manolis Savva, Nicholas Kong, Arti Chhajta, Li Fei-Fei, Maneesh Agrawala and Jeffrey Heer
User Interface Software and Technology (UIST), Oct 2011. pp. 393-402.
PDF | Image Corpus | Code